ANU Archives¶
Current version: v1.1.2¶
See below for information on running these notebooks in a live computing environment. Or just take them for a spin using Binder.


Sydney Stock Exchange records¶
The aim of this project is to try and extract useful data from the Sydney Stock exchange stock and share lists held by the ANU Archives. As the content note indicates:
These are large format bound volumes of the official lists that were posted up for the public to see - 3 times a day - forenoon, noon and afternoon - at the close of the trading session in the call room at the Sydney Stock Exchange. The closing prices of stocks and shares were entered in by hand on pre-printed sheets.
There are 199 volumes covering the period from 1901 to 1950, containing more than 70,000 pages. Each page is divided into columns. The number of columns varies across the collection. Each column is divided into rows labelled with printed company or stock names. The prices are written alongside the company names.
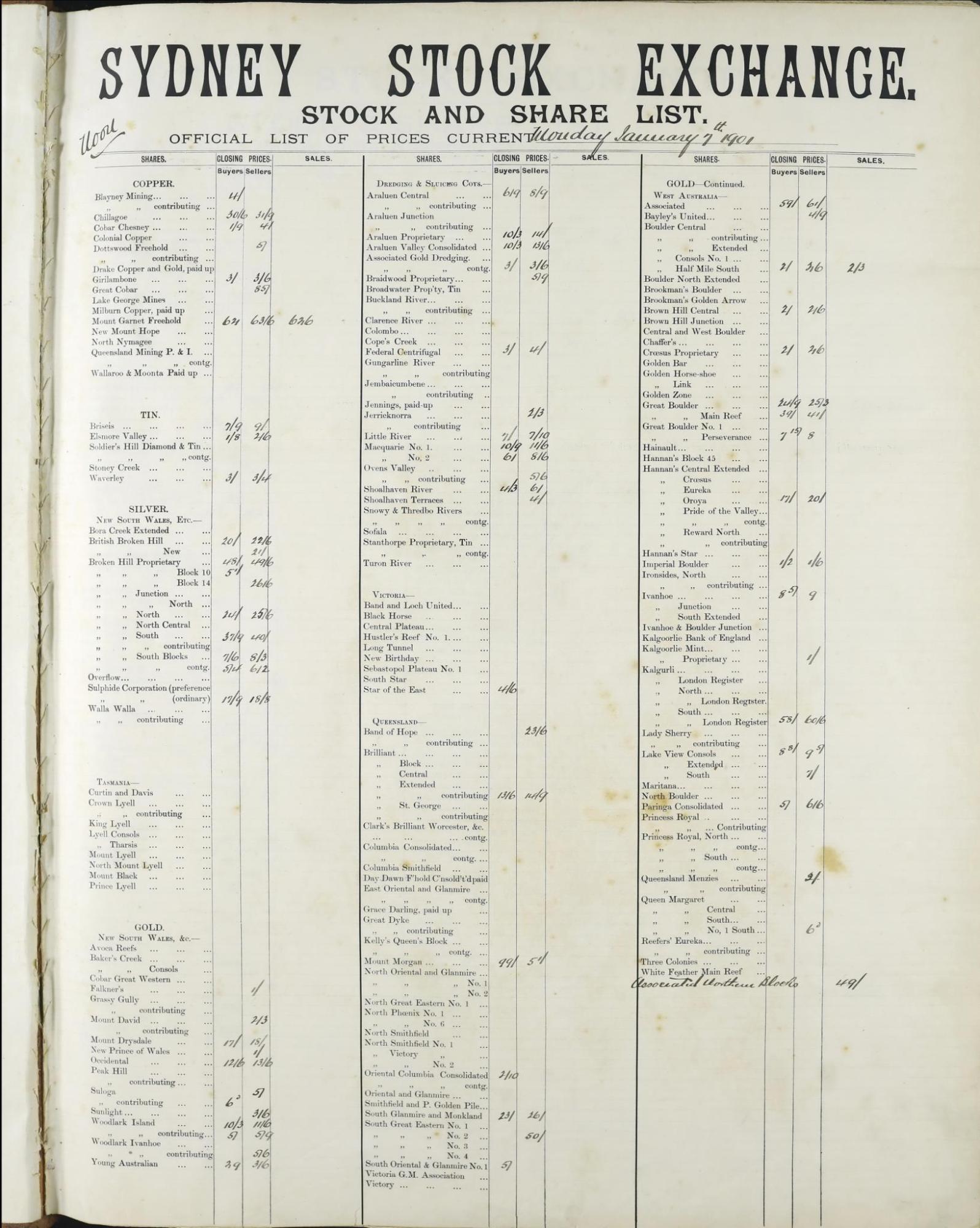
We're currently working on ways of extracting company and share names, as well as the handwritten prices, from the digitised images. For more information see this repository. The notebooks below provide ways of navigating, visualising, and using the digitised pages.
Summary information about volumes¶
This notebook collates links and metadata relating to the 199 bound volumes in the Sydney Stock Exchange collection. It includes links to archival descriptions, records and PDFs in the research repository, and collections of individual page images stored on CloudStor. It also generates a CSV file with metadata for each page in the volume. For each volume a calculation of its completeness is attempted – this is done by comparing the number of pages for each date with the expected number of pages and adding up the results.
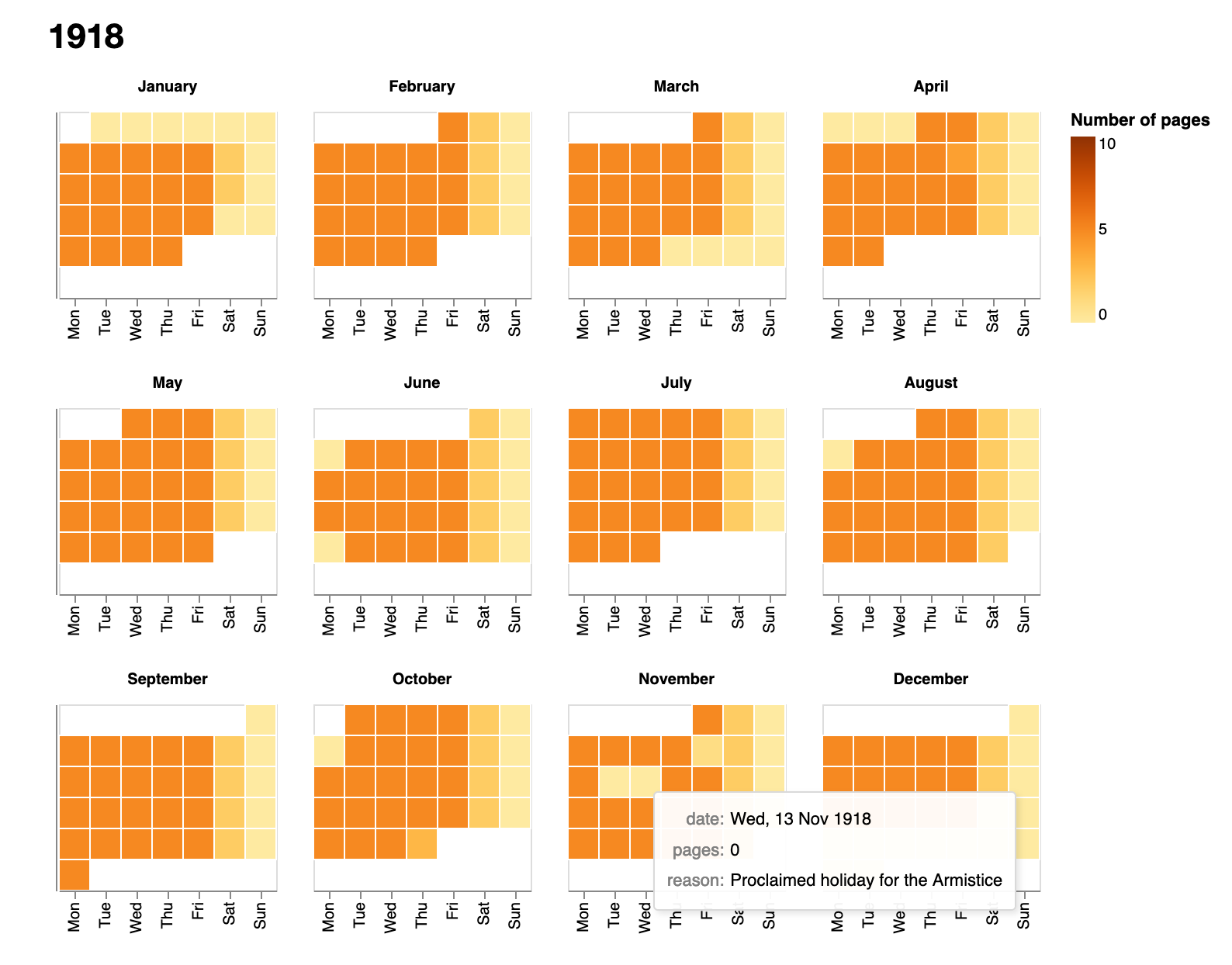
Calendar view of the complete collection¶
This notebook helps you see the number of stock and share sheets in the bound volumes from the Sydney Stock Exchange for each day from 1901 to 1950. You can pick out major changes such as when the number of sheets per day changed, and when Saturday trading finished. However, the bound volumes are not always complete. You'll notice some days have fewer sheets than expected or none at all. In using these records it's important to be aware of the gaps.
Display information about a single day's trading¶
Select a date and this notebook will display information about any sheets that are available from this day. It notes where pages seem to be missing, and loads images of the pages for examination.
Display details of pages within a date range¶
Select a date range and this notebook will display information about available sheets from all the days within the range. It notes where pages seem to be missing, and provides links to download page images.
Visualise page data¶
This notebook explores the aggregated page metadata from all 199 volumes.

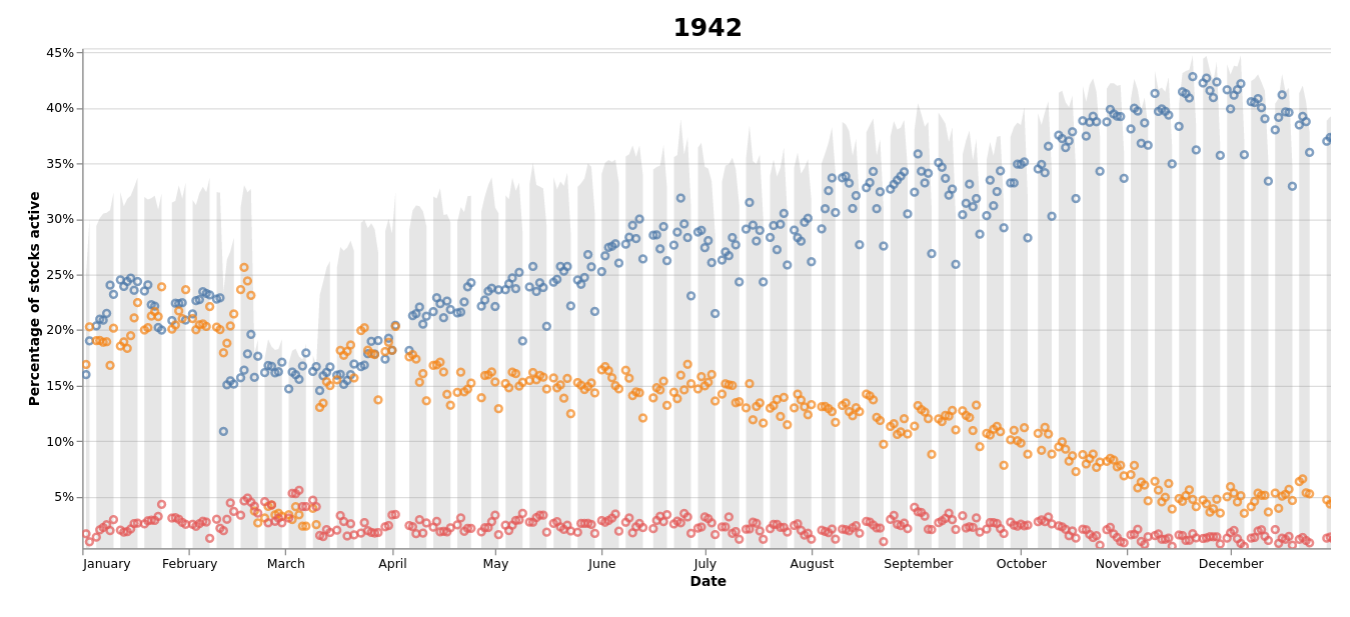
Visualise activity¶
This notebook visualises the amount of activity each day of trading by looking at the proportion of stocks that have prices recorded against them either in the 'Buyers', 'Sellers', or 'Business done' columns. Each point is linked to an online database, so you can explore in detail what was happening on any day.
- Download from GitHub
- View using NBViewer
- Run live on Binder
- View the output of this notebook as an HTML page
Data files¶
- CSV-formatted list of all 70,000+ pages in the bound volumes including their date and session (Morning, Noon, Afternoon). Duplicate images are excluded.
- CSV-formatted list of all dates within the period of the volumes. Includes the number of pages available for each date, and the number of pages expected (the number of pages produced each day changes across the collection). On dates with no pages, the
reasonfield is used to record details of holidays or other interruptions to trading (some with links to Trove). - CSV-formatted list of holidays in NSW from 1901 to 1950.
- Full data about missing, misplaced, and duplicated pages is saved in
page_data_master.py. This data is combined with the holiday data to generate the complete page and date lists above. - Print and handwritten data extracted from the images using Amazon Textract have been saved in a series of CSV files available from Cloudstor. There's one file per year, and each row in the CSV represents a single column row. This data is in the process of being checked and cleaned, and is likely to change. The easiest way to explore this data is through the Datasette interface which provides fulltext and structured searching.
Run these notebooks¶
There are a number of different ways to use these notebooks. Binder is quickest and easiest, but it doesn't save your data. I've listed the options below from easiest to most complicated (requiring more technical knowledge).
Using ARDC Binder¶

Click on the button above to launch the notebooks in this repository using the ARDC Binder service. This is a free service available to researchers in Australian universities. You'll be asked to log in with your university credentials. Note that sessions will close if you stop using the notebooks, and no data will be preserved. Make sure you download any changed notebooks or harvested data that you want to save.
See Using ARDC Binder for more details.
Using Binder¶
![]()
Click on the button above to launch the notebooks in this repository using the Binder service (it might take a little while to load). This is a free service, but note that sessions will close if you stop using the notebooks, and no data will be saved. Make sure you download any changed notebooks or harvested data that you want to save.
See Using Binder for more details.
Using Reclaim Cloud¶

Reclaim Cloud is a paid hosting service, aimed particularly at supported digital scholarship in hte humanities. Unlike Binder, the environments you create on Reclaim Cloud will save your data – even if you switch them off! To run this repository on Reclaim Cloud for the first time:
- Create a Reclaim Cloud account and log in.
- Click on the button above to start the installation process.
- A dialogue box will ask you to set a password, this is used to limit access to your Jupyter installation.
- Sit back and wait for the installation to complete!
- Once the installation is finished click on the 'Open in Browser' button of your newly created environment (note that you might need to wait a few minutes before everything is ready).
See Using Reclaim Cloud for more details.
Running in a container on your own computer¶
GLAM Workbench repositories are stored as pre-built container images on quay.io. You can run these containers on your own computer to set up a virtual machine with everything you need to use the notebooks. This is free, but requires more technical knowledge – you'll have to install Podman on your computer, and be able to use the command line.
- Install Podman.
- In a terminal, run the following command:
podman run --rm -p 8888:8888 quay.io/glamworkbench/anu-archives jupyter lab --ip=0.0.0.0 --port=8888 --ServerApp.token="" --LabApp.default_url="/lab/tree/index.ipynb" - It will take a while to download and configure the container image. Once it's ready you'll see a message saying that Jupyter Notebook is running.
- Point your web browser to
http://127.0.0.1:8888 - When you've finished, download any files or data you want to keep from Jupyter Lab, and enter Ctrl+C int the terminal.
See Running in a container on your own computer for more details.
Setting up on your own computer¶
If you know your way around the command line and are comfortable installing software, you might want to set up your own computer to run these notebooks. You'll need to have recent versions of Python and Git installed. I use pyenv, pyenv-virtualenv, and pip-tools to create and manage Python versions and environments.
In a terminal:
- Create a Python virtual environment (Python >= 3.10 should be ok):
pyenv virtualenv 3.10.12 anu-archives - Activate the virtual environment:
pyenv local anu-archives - Use
git cloneto create a local version of the GLAM Workbench repository:git clone https://github.com/GLAM-Workbench/anu-archives.git - Use
cdto move into the newly-cloned folder:cd anu-archives - Run
pip install pip-toolsto installpip-tools. - Run
pip-sync requirements.txt dev-requirements.txtto install the required Python packages. - Start Jupyter with
jupyter lab– a browser window should open automatically. If not, copy and paste the url from the command line to your web browser. - To shut down your Jupyter Lab session enter Ctrl+C in the terminal.
See Using Python on your own computer for more details.
Contributors¶
Cite as¶
Sherratt, Tim. (2022). GLAM-Workbench/anu-archives (version v1.1.2). Zenodo. https://doi.org/10.5281/zenodo.6029301
![]()